Рекомендации по созданию и мониторингу производительности виртуальных машин
Posted by j3qx на 10 декабря, 2016
Типы дисков виртуальных машины
Zeroed thick disks (lazy zeroed thick disks). Все пространство такого диска выделяется в момент создания, при этом блоки не очищаются от данных, которые находились там ранее. При первом обращении виртуальной машины к новому блоку происходит его очистка. Таким образом, эти диски более безопасны, однако при первом обращении к блоку — теряется производительность системы ввода-вывода на операцию очистки. При последующих обращениях — производительность идентична дискам типа Eager zeroed thick. Этот тип диска создается по умолчанию через VMware vSphere Client для виртуальных машин. Преимущество дисков Zeroed thick disks — безопасность и быстрота создания, недостаток — производительность при первом обращении к блоку.
Eager zeroed thick disks. Все пространство такого диска выделяется в момент создания, при этом блоки очищаются от данных, которые находились там ранее. Далее происходит обычная работа с блоками без очистки. Преимущество такого диска — производительность и безопасность, недостаток — долгое время создания
Диски типа Thin («тонкие диски»). Эти диски создаются минимального размера и растут по мере их наполнения данными до выделенного объема. При выделении нового блока — он предварительно очищается. Эти диски наименее производительны (выделение нового блока и его очистка), однако наиболее оптимальны для экономии дискового пространства на системе хранения данных.
Более подробная информация http://www.vmgu.ru/articles/vmware-esx-vsphere-vmdk-thin-thick
Рекомендации по дискам
- Тестовые среды и вспомогательные, не критичные сервера- рекомендую использовать диски типа thin (thin provision).
- Для серверов, с большой нагрузкой на дисковую подсистему, а именно базы данных, Exchange и т.п. – использовать диски типа eager zeroed thick disks
- Для критичных серверов инфраструктуры и бизнеса – использовать zeroed thick disks, что гарантирует, что у данных серверов будет всегда необходимое им место ив случае дефицита места на storage, они не пострадают
Производительность виртуальной машины. Память
Первоисточник на русском языке http://www.vmgu.ru/news/vmware-vsphere-memory-vm
Итак, если открыть вкладку Summary в vSphere Client для виртуальной машины, мы увидим вот такую картину:
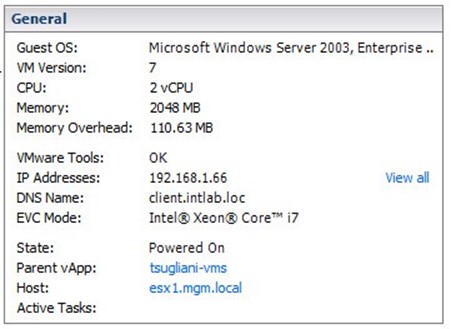
Здесь есть 2 главных параметра:
- Memory — это то количество оперативной памяти, которое вы выделили виртуальной машине при создании. За это количество гостевая ОС не выйдет при ее использовании. Это же количество памяти вы увидите в гостевой ОС.
- Memory Overhead — это количество памяти, которое может потребоваться гипервизору на поддержание работы виртуальной машины сверх используемой памяти (т.е. расчетные накладные расходы на виртуализацию, но не текущие).
Далее мы видим панель Resources, здесь есть такие показатели:

- Consumed Host Memory — это количество физической памяти хоста ESX, выделенной виртуальной машине. Обычно это значение не больше значения Memory на предыдущей картинке. Но может быть и больше, поскольку Consumed Host Memory включает в себя и Memory Overhead, но не с картинки выше, а реально используемый гипервизором Overhead (о котором будет идти речь ниже). И важный момент — счетчик Consumed для Memory на вкладке «Performance» не включает в себя Overhead.
- Active Guest Memory — это количество памяти, которое по мнению гипервизора VMkernel активно используется гостевой операционной системой. Вычисляется этот параметр на базе статистических показателей. То есть, если ОС не очень активно использует память, то можно ей ее немного подрезать в условиях нехватки ресурсов.
Теперь идем на вкладку «Resource Allocation». Здесь все немного сложнее:
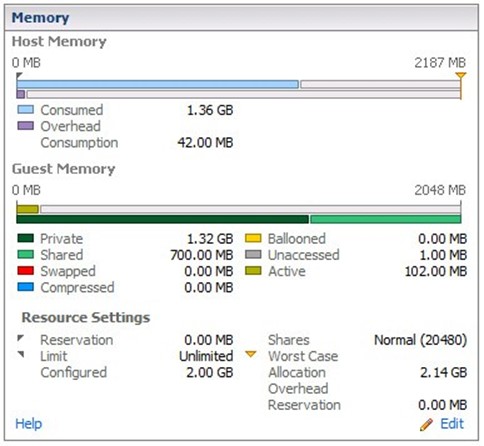
Появляются вот такие показатели:
Для Host Memory (видим, что это 2187 МБ = сконфигурированная память 2048 МБ + Overhead):
- Consumed — это, опять-таки, объем потребляемой виртуальной машиной физической памяти хоста ESX (постоянно меняется). И он включает в себя накладные расходы гипервизора по памяти.
- Overhead Consumption — это текущий объем затрат памяти на поддержание виртуальной машины (здесь 42 МБ в отличие от расчетного в 110 МБ)
А формула такова: Consumed = Private + Overhead Comsumption
Для Guest Memory (2048 МБ сконфигурировано в настройках):
- Private — это объем памяти физически хранимый хостом для виртуальной машины (см. формулу выше).
- Shared — это объем памяти, который отдается другим виртуальным машинам от разницы между сконфигурированным объемом (Configured Memory) и потребляемым (Consumed). Суть в том, что ОС Windows при загрузке очищает всю память виртуальной машины, но потом эти пустые страницы приложениями не используются. Поэтому гипервизор отдает их другим ВМ, пока ВМ, владеющая памятью не потребует их. Эти страницы и есть Shared. Как мы видим, Private + Shared = Guest Memory.
- Swapped — это объем памяти, ушедший в файл подкачки vswp. То есть это не файл подкачки Windows, а файл подкачки в папке с виртуальной машиной. Само собой этот показатель должен быть нулевым или совсем небольшим, поскольку своппинг, который делает ESX (а точнее VMkernel) — это плохо, т.к. он не знает (в отличие от Windows), какие страницы нужно складывать в своп, поэтому кладет все подряд.
- Compressed — это объем памяти, который получен после сжатия страниц с помощью механизма Memory Compression (то есть, хранимый в VM Compression Cache).
- Ballooned — это объем памяти, который забрал balloon-драйвер (vmmemctl), чтобы отдать ее другим нуждающимся виртуальным машинам.
- Unaccessed — это память, к которой гостевая ОС ни разу не обращалась (у Windows — это близко к нулю, так как она обнуляет память при загрузке, у Linux должно быть как-то иначе).
- Active — опять-таки, активно используемая память на основе статистики гипервизора.
На хорошем и производительном хосте VMware ESX метрики Compressed, Ballooned, Unaccessed — должны быть около нуля, так как это означает что машины не борются за ресурсы (то есть не сжимают страницы и не перераспределяют память между собой). Ну и, конечно, если показатель Active маленький, стоит задуматься об урезании памяти (но сначала посмотрите в гостевую ОС, она лучше знает, чем гипервизор, все-таки).
Ну и последняя секция Resource Settings:
- Reservation, Limit, Shares, Configured — смотрим сюда.
- Worst Case Allocation — это сколько будет выделено виртуальной машине при самом плохом раскладе (максимальное использование ресурсов), то есть вся память будет использоваться, да еще и накладные расходы будут (т.е., Configured + максимальный Overhead).
- Overhead Reservation — это сколько зарезервировано памяти под Overhead гипервизором.
Рекомендации по памяти
Правильно подходите к сайзингу ресурсов, не нужно выделять виртуальной машине по 40Гб памяти и 20 процессоров, если реально машина запросила всего 4 и 2 CPU. Если вы наблюдаете у нескольких машин параметр Shared отличный от нуля, значит на хосте дефицит ресурсов памяти, что приводит к борьбе за ресурсы
Производительность виртуальной машины. Процессор
Первоисточники на русском языке: http://vmind.ru/2012/07/19/nyuansy-cpu-ready/
http://www.vmgu.ru/news/vmware-vsphere-esxtop-cpu
CPU Ready – это метрика, показывающая сколько времени процесс стоял в ожидании процессорного времени.
Имеются следующие предпосылки к высокому CPU Ready:
1) Переиспользование (Oversubscription) процессора. То есть соотношение количества физических процессоров (PCPU или «ядер») к количеству виртуальных процессоров (VCPU – процессоров виртуальных машин). Согласно vSphere 5Configuration Maximums на одно ядро можно впихнуть до 25 виртуальных процессоров. Чудес не бывает – эти процессоры должны быть должным образом ненагружены, чтобы такой фокус удался. VMKernel предлагает следующие варианты:
— от 1:1 до 1:3 – все ок;
— от 1:3 до 1:5 – могут быть проблемы из-за конкуренции за ресурсы;
— от 1:5 — скорее всего будут проблемы.
Тут же стоит помнить о Hyper-Threading: эта технология удваивает количество PCPU, но полноценно выполняться код может только на одном из пары.
Посмотреть показатель CPU Ready на вкладке Perfomance, выбрать режим Advanced, switch to CPU, chart options, выбрать необходимый виртуальный процессор или всю машину, и в counters выбрать параметр READY
Рекомендации
- Иметь четкое представление сколько vCPU выделено на хосте и сколько физических CPU на нем есть
- Выделяя vCPU, руководствоваться принципом, лучше меньшое количество vCPU, чем много. В случае если приложении «тормозит» на вкладке performance смотреть потребление CPU, если потребление меньше, чем максимальная производительность ядра, надо искать в другом причину, если производительность, уперлась в производительность физического ядра, то добавлять vCPU
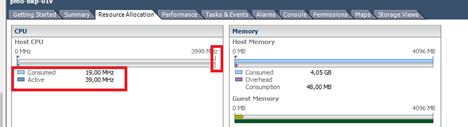
Картинка выше иллюстрирует, что даже выдели я виртуальной машине 4 ядра, быстрее она работать не станет, так как ей для обычной работы достаточно очень мало ресурсов, но при необходимости, она может запросить почти 4 Ггц.
- Если хост сильно загружен, количество vCPU реально нужно большое и используется, то дальнейшая оптимизация – это изменение веса sharing ресурсного пула/виртуальной машины, жесткое резервирование по необходимому вам типу ресурсов

Оставьте комментарий